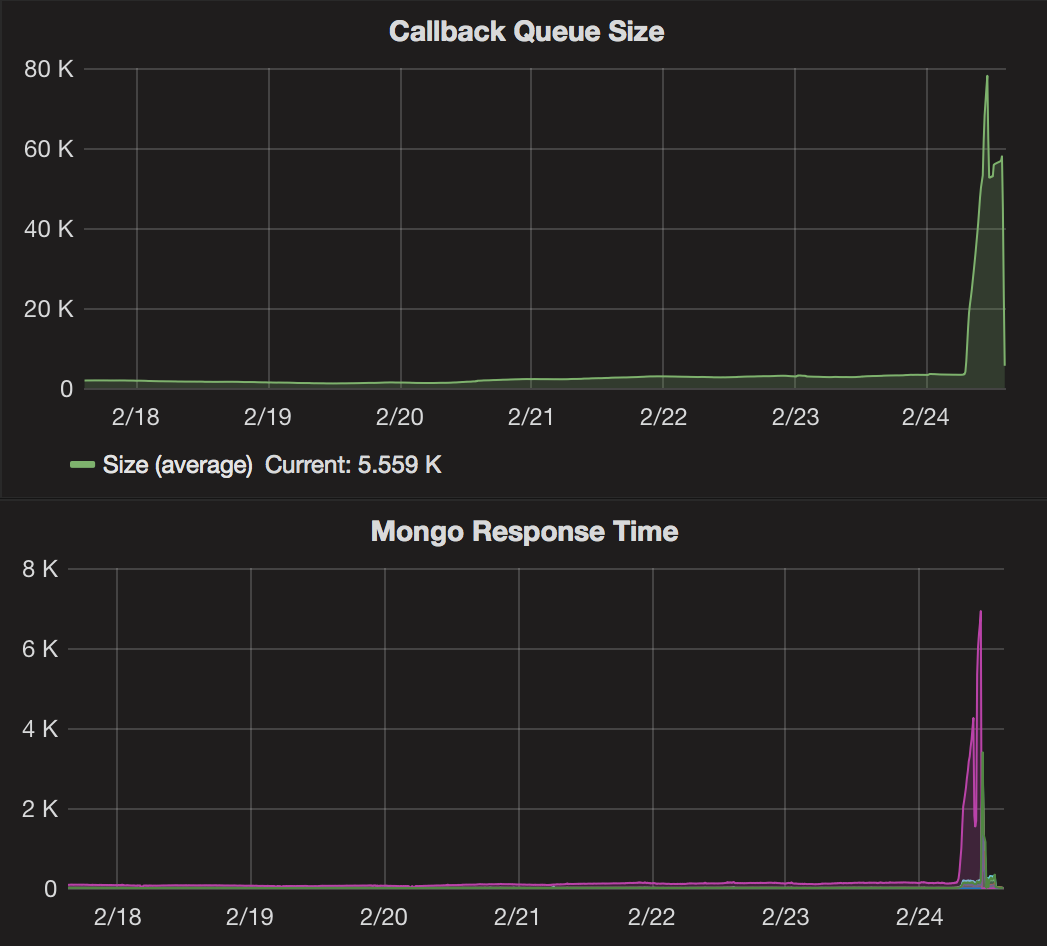
Now, the nature of a queue is precisely to allow for a build up of entries that later can be processed in an orderly manner. The enqueueing of callbacks continued to work throughout this incident - meaning no callback was lost because of this.
The problem, however, was with the storage component (MongoDB) in the queue eco system. This morning it became slow to respond to the queries from the queue consumers - asking for an entry from queue to process.
The build-up in queue size triggered an alarm with our operations team, who analyzed the situation and made two observations:
- the traffic pattern was normal
- no code or operations changes had been deployed recently
In a normal operations situation, there are only few processable items in the queue, and most of the queue consumers are dormant - waiting to process entries if queue size is increasing. As the queue size did in fact increase, the consumers sprang to life - asking the database for an entry and thus triggering an database read-lock congestion and an even slower response time from database.
We were now facing two tasks; 1) find the root cause of the slow queries, and 2) manage the read-lock congestion and keep the failures from cascading to other systems.
Analyzing the queries revealed that the MongoDB query optimizer had stopped using a previously working and battle tested index for no apparent reason. Instead it chose to use an old and ineffective index. At this point in time we can’t explain why - more analyzing will have to be done.
After we managed to get the MongoDB query optimizer to use the right index, the consumers (which had been reduced in numbers to avoid read-lock congestion) were re-activated and dissolved the queue in a matter of minutes - and normal operations were resumed.
Customer impact
This incident mainly affected customers using the v7 protocol via the proxy as the callbacks from here are synchronous and thus are very much vulnerable to a slow responding database. While payments through the proxy were accepted, the callback in most cases was not dispatched in time for customers to update their systems while the consumer was waiting for confirmation.
Other customers (incl. v10 users) relying on callbacks in their payment flow to eg. mark orders as paid and show a receipt on the continue-url are likely to have have been affected as well.
Further, for a short period of time, the failure did cascade to other systems resulting in timeouts from API and subsequently the Payment Window (v10).
Throughout the incident there was a general increase in API response time - from a normal 90-130ms to 350-410ms.
Customer resolution - short term
All callbacks were dispatched within a few minutes after the issue was fixed. It is also possible to check the status of payments using either manually via our manager or programmatically via our API.
Tip: If using API then use GET /payments?order_id=<your order id> to retrieve payment without having the actual payment-id.
Customer resolution - long term
If you are still using the v7 protocol we strongly urge you to update to v10. While the proxy does handle some issues with the v7 protocol, it remains more vulnerable to abnormal operation situations.
This might seem like a daunting task, but it might “just” be a matter of upgrading a module or a few hours of programming. Please do not hesitate to ask our support for help and advice.
Lessons learned
I think in most cases where an investigation is completed and a cause is determined, the detectives are - in retrospect - left with a feeling of “if only”. It is always a goal to sharpen our analytical/detective skills and this experience certainly adds to that.
We have been in the process of migrating systems from MongoDB to traditional RDBMS’ for some time - to simplify our stack and focus on fewer components. This process will be sped up.
We’ve also made some adjustments to our monitoring services.
Further, it is our ambition to be open and provide top notch communication in situations like this using our public status site , and today we didn’t quite live up to that. This is something we will work hard on improving.
Finally, we are of course sorry for the inconvenience this incident may have caused our customers. Our support crew is standing by to answer any questions you may have.
Best regards